IN TODAY'S SIGNAL |
|
Read time: 4 min 35 sec |
|
🎖️ Top News
📌 AI Conference
⚡️ Trending Signals
📌 Assembly AI
📦 Top HF Models
-
ProMax Model: ControlNet model for high-resolution image generation and editing.
-
Kolors: latent diffusion model for high-quality bilingual text-to-image generation.
-
Meta's Chameleon: early-fusion model for mixed-modal text and image understanding/generation.
📚 Top HF Datasets
-
UpVoteWeb: 2024 Reddit dataset, 10M entries, 95% language detection accuracy, supports NLP tasks.
-
FaceCaption-15M: 15M face image-caption pairs, high BRISQUE scores, detailed captions.
-
xlam-function-calling-60k: 60K function-calling examples, structured JSON format, 21 categories.
🧠 Tutorial
|
|
|
|
|
If you're enjoying AlphaSignal please forward this email to a colleague.
It helps us keep this content free. |
|
|
|
TOP NEWS |
|
Language Models |
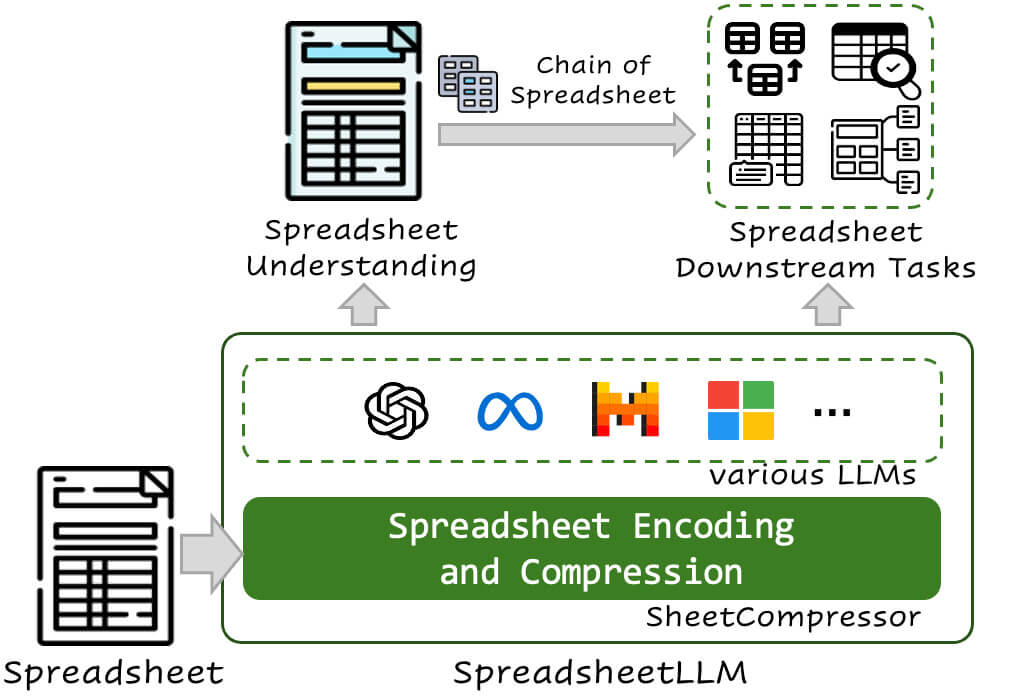
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models |
|
⇧ 1914 Likes |
 |
What's New |
|
Microsoft researchers unveiled “SpreadsheetLLM,” an AI model designed to address the complexities of applying AI to spreadsheets.
Traditional LLMs struggle with spreadsheets due to their structured data and embedded formulas. SpreadsheetLLM encodes spreadsheet contents into a format that LLMs can effectively analyze and understand.
SheetCompressor optimizes spreadsheet encoding
The core innovation in SpreadsheetLLM is the SheetCompressor module, which efficiently compresses and encodes spreadsheets. It includes:
- Structural-anchor-based compression: Identifies key rows and columns that define the layout and removes repetitive, non-informative data, creating a condensed version of the spreadsheet.
- Inverse index translation: Converts spreadsheet data into a dictionary format that indexes non-empty cells, optimizing token usage and preserving data integrity.
- Data-format-aware aggregation: Clusters adjacent cells with similar formats, reducing the number of tokens needed while retaining essential data types and structures.
Performance metrics show significant improvements
The SheetCompressor module achieves an average compression ratio of 25 times and a state-of-the-art 78.9% F1 score, surpassing existing models by 12.3%. In GPT-4's in-context learning setting, it improves spreadsheet table detection tasks by 25.6%, demonstrating its effectiveness.
SpreadsheetLLM enhances and automates various spreadsheet tasks
By enabling LLMs to reason over spreadsheet data, answer queries, and generate new spreadsheets from natural language prompts, SpreadsheetLLM offers practical applications. It can:
- Automate routine data analysis tasks
- Provide intelligent insights and recommendations
- Simplify data cleaning, formatting, and aggregation
|
|
|
| CHECK THE PAPER |
|
|
|
 |
The AI Conference 2024: Share 2 Days with the Brightest Minds in AI |
|
The AI Conference brings together OpenAI, Meta, DeepMind and many more.
- Engage with 60+ speakers leading the AI revolution
- Network, collaborate, and co-create with industry pioneers
- Explore topics including AGI, AI in enterprise, building with AI, and more!
This week only, save $350 using discount code:
"Alpha24" |
| REGISTER TODAY |
|
partner with us |
|
|
|
TRENDING SIGNALS |
|
Language Models |
Mistral releases Codestral Mamba, a Mamba2 LLM for code generation and MathΣtral, a math reasoning model |
|
⇧ 888 Likes |
|
|
|
Implementation |
|
|
|
⇧ 312 Likes |
|
|
|
Claude |
|
|
|
⇧ 2419 Likes |
|
|
|
Tutorial |
|
|
|
⇧ 166 Likes |
|
|
|
Models |
|
|
|
⇧ 161 Likes |
|
|
|
|
|
|
|
|
Build Voice-Driven AI Products with Just 10 Lines of Code |
|
Build with industry‑leading Speech-to-Text models. The API offers high accuracy in transcribing accented speech, background noise, and natural conversations.
Join 200,000+ developers using AssemblyAI. |
|
Get 100 free hours ↗️ |
|
|
|
TOP OF HUGGINGFACE |
|
Models |
-
controlnet-union-sdxl-1.0: An advanced image generation model based on ControlNet architecture. It supports 12 control types and 5 advanced editing features, allowing for high-resolution, multi-condition image creation with minimal computational increase.
-
Kolors: A large-scale text-to-image model using latent diffusion, excelling in visual quality and semantic accuracy. It supports both Chinese and English, enabling high-quality image generation from text inputs.
-
Chameleon: A mixed-modal early-fusion Chameleon model (7B and 34B variants). A family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence.
|
|
|
|
Datasets |
-
UpVoteWeb : Reddit 2024 dataset. Anonymized posts/comments. Includes metadata: subreddit, score, language. 10M entries, 150 tokens average. 95% language detection accuracy. Supports text classification, sentiment analysis, language modeling tasks.
-
FaceCaption-15M: helps you analyze and describe facial images at scale. It contains 15M+ face image-caption pairs with diverse attributes.
-
xlam-function-calling-60k: The dataset contains 60,000 function-calling examples across 21 categories, generated by AI models and verified for quality. It includes queries, available tools, and corresponding answers in a structured JSON format.
|
|
|
|
|
|
|
PYTORCH TIP |
Efficient Feature Engineering with Pandas apply and NumPy Vectorization |
|
Feature engineering is critical in machine learning, but it can be slow when processing large datasets. Many data scientists use pandas' apply method for row-wise operations, which can be inefficient. A faster alternative is leveraging NumPy's vectorization.
Instead of using pandas' apply method, use NumPy's vectorized operations to improve the speed of feature engineering tasks.
Why This Works
NumPy operations are implemented in C, which makes them much faster than the equivalent operations in pure Python. By using NumPy arrays and vectorized operations, you reduce the overhead associated with pandas' apply method, resulting in significant performance improvements.
Performance Comparison
To illustrate the performance gain, let's compare the execution time of both methods: |
import numpy as np
import pandas as pd
import time
# Define the complex function
def complex_function(x1, x2):
return np.log(x1 + 1) * np.sqrt(x2)
# Generate sample data
df = pd.DataFrame({
'feature1': np.random.rand(1000000),
'feature2': np.random.rand(1000000)
})
# Using pandas apply (slower)
start_time = time.time()
df['new_feature_apply'] = df.apply(lambda row: complex_function(
row['feature1'], row['feature2']), axis=1)
apply_duration = time.time() - start_time
# Using NumPy vectorization (faster)
start_time = time.time()
df['new_feature_vectorized'] = complex_function(df['feature1'].values,
df['feature2'].values)
vectorized_duration = time.time() - start_time
print(f"Apply duration: {apply_duration:.2f} seconds")
print(f"Vectorized duration: {vectorized_duration:.2f} seconds")
#Apply duration: 10.07 seconds
#Vectorized duration: 0.01 seconds
|
|
|
|
LAST WEEK'S GREATEST HITS |
|
|
|
|
|
|